023-10-18 16:40:00 java.util.concurrent.CompletionException: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources. at org.apache.flink.runtime.scheduler.DefaultExecutionDeployer.lambda$assignResource$4(DefaultExecutionDeployer.java:227) at java.util.concurrent.CompletableFuture.uniHandle(CompletableFuture.java:822) at java.util.concurrent.CompletableFuture$UniHandle.tryFire(CompletableFuture.java:797) at java.util.concurrent.CompletableFuture.postComplete(CompletableFuture.java:474) at java.util.concurrent.CompletableFuture.completeExceptionally(CompletableFuture.java:1977) at org.apache.flink.runtime.jobmaster.slotpool.PendingRequest.failRequest(PendingRequest.java:88) at org.apache.flink.runtime.jobmaster.slotpool.DeclarativeSlotPoolBridge.cancelPendingRequests(DeclarativeSlotPoolBridge.java:185) at org.apache.flink.runtime.jobmaster.slotpool.DeclarativeSlotPoolBridge.failPendingRequests(DeclarativeSlotPoolBridge.java:408) at org.apache.flink.runtime.jobmaster.slotpool.DeclarativeSlotPoolBridge.notifyNotEnoughResourcesAvailable(DeclarativeSlotPoolBridge.java:396) at org.apache.flink.runtime.jobmaster.JobMaster.notifyNotEnoughResourcesAvailable(JobMaster.java:887) at sun.reflect.GeneratedMethodAccessor43.invoke(Unknown Source) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.lambda$handleRpcInvocation$0(AkkaRpcActor.java:301) at org.apache.flink.runtime.concurrent.akka.ClassLoadingUtils.runWithContextClassLoader(ClassLoadingUtils.java:83) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcInvocation(AkkaRpcActor.java:300) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleRpcMessage(AkkaRpcActor.java:222) at org.apache.flink.runtime.rpc.akka.FencedAkkaRpcActor.handleRpcMessage(FencedAkkaRpcActor.java:84) at org.apache.flink.runtime.rpc.akka.AkkaRpcActor.handleMessage(AkkaRpcActor.java:168) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:24) at akka.japi.pf.UnitCaseStatement.apply(CaseStatements.scala:20) at scala.PartialFunction.applyOrElse(PartialFunction.scala:127) at scala.PartialFunction.applyOrElse$(PartialFunction.scala:126) at akka.japi.pf.UnitCaseStatement.applyOrElse(CaseStatements.scala:20) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:175) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176) at scala.PartialFunction$OrElse.applyOrElse(PartialFunction.scala:176) at akka.actor.Actor.aroundReceive(Actor.scala:537) at akka.actor.Actor.aroundReceive$(Actor.scala:535) at akka.actor.AbstractActor.aroundReceive(AbstractActor.scala:220) at akka.actor.ActorCell.receiveMessage(ActorCell.scala:579) at akka.actor.ActorCell.invoke(ActorCell.scala:547) at akka.dispatch.Mailbox.processMailbox(Mailbox.scala:270) at akka.dispatch.Mailbox.run(Mailbox.scala:231) at akka.dispatch.Mailbox.exec(Mailbox.scala:243) at java.util.concurrent.ForkJoinTask.doExec(ForkJoinTask.java:289) at java.util.concurrent.ForkJoinPool$WorkQueue.runTask(ForkJoinPool.java:1056) at java.util.concurrent.ForkJoinPool.runWorker(ForkJoinPool.java:1692) at java.util.concurrent.ForkJoinWorkerThread.run(ForkJoinWorkerThread.java:157) Caused by: java.util.concurrent.CompletionException: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources. at java.util.concurrent.CompletableFuture.encodeThrowable(CompletableFuture.java:292) at java.util.concurrent.CompletableFuture.completeThrowable(CompletableFuture.java:308) at java.util.concurrent.CompletableFuture.uniApply(CompletableFuture.java:593) at java.util.concurrent.CompletableFuture$UniApply.tryFire(CompletableFuture.java:577) ... 36 more Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources.
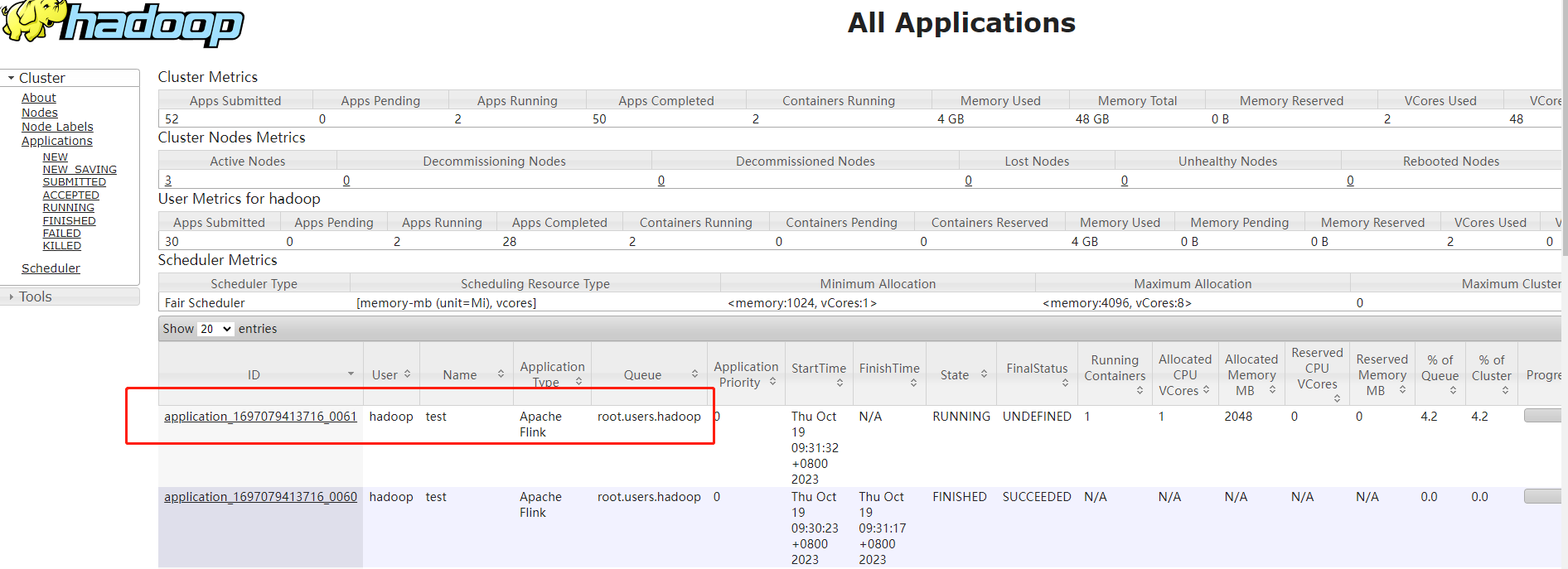
2023-10-19 09:28:38,015 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - YARN application has been deployed successfully. 2023-10-19 09:28:38,016 INFO org.apache.flink.yarn.YarnClusterDescriptor [] - Found Web Interface hadoop003:20604 of application 'application_1697079413716_0061'. JobManager Web Interface: http://hadoop003:20604 2023-10-19 09:28:38,256 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - The Flink YARN session cluster has been started in detached mode. In order to stop Flink gracefully, use the following command: $ echo"stop" | ./bin/yarn-session.sh -id application_1697079413716_0061 If this should not be possible, then you can also kill Flink via YARN's web interface or via: $ yarn application -kill application_1697079413716_0061 Note that killing Flink might not clean up all job artifacts and temporary files.
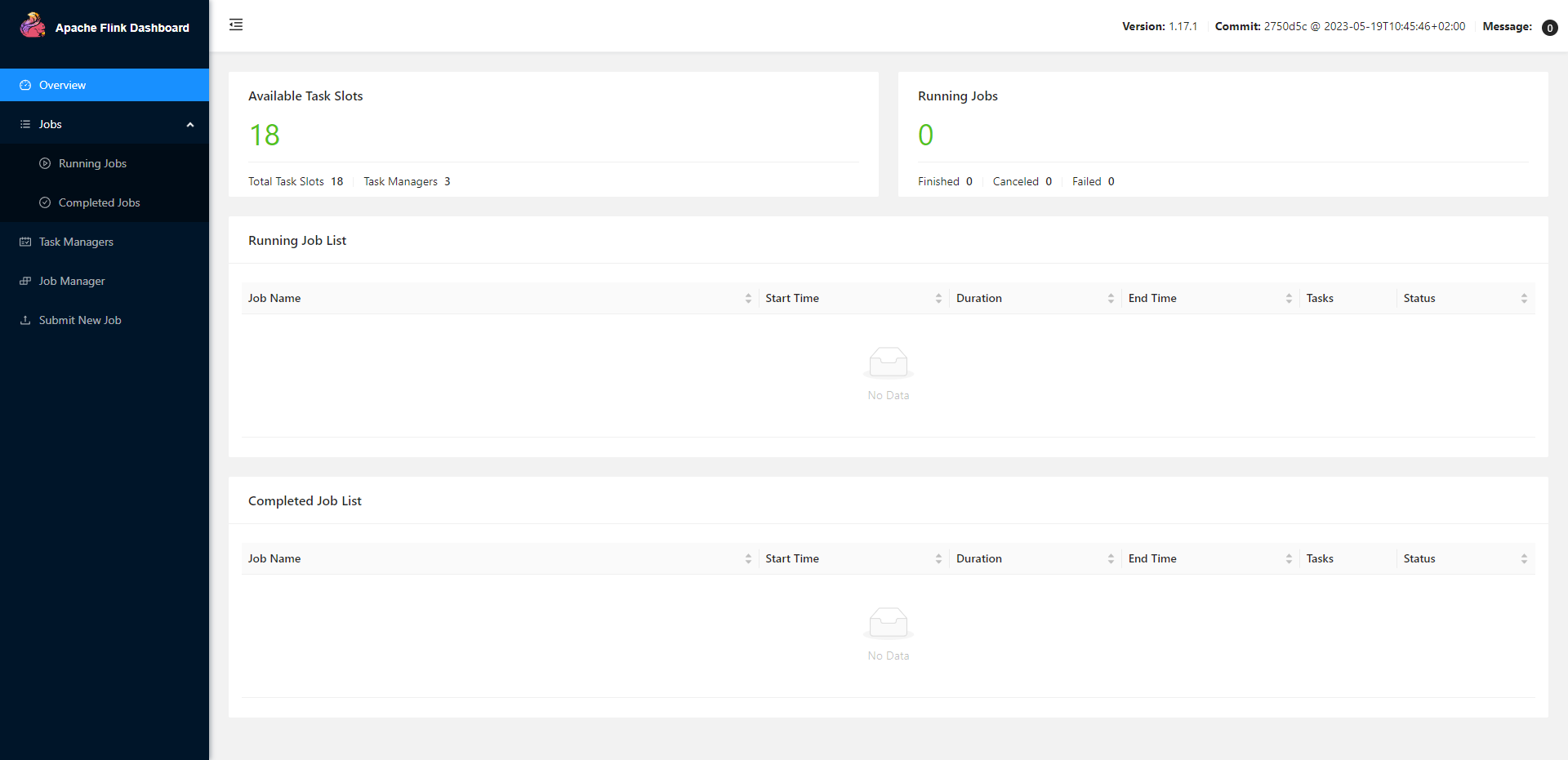
2)提交作业
(1)通过Web UI提交作业
这种方式比较简单,与上文所述Standalone部署模式基本相同。
(2)通过命令行提交作业
① 通过flink提供的测试作业:WordCount.jar的进行测试,如果是个人开发的作业,需要上传到flink集群。
② 执行以下命令将该任务提交到已经开启的Yarn-Session中运行。
1
[hadoop@hadoop001 flink]$ bin/flink run -s test -c org.apache.flink.examples.java.wordcount.WordCount examples/batch/WordCount.jar
2023-10-19 09:32:49,402 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-hadoop. java.lang.NoSuchMethodError: org.apache.commons.cli.CommandLine.hasOption(Lorg/apache/commons/cli/Option;)Z at org.apache.flink.client.cli.CliFrontendParser.createSavepointRestoreSettings(CliFrontendParser.java:631) at org.apache.flink.client.cli.ProgramOptions.<init>(ProgramOptions.java:119) at org.apache.flink.client.cli.ProgramOptions.create(ProgramOptions.java:192) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:235) at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1095) at org.apache.flink.client.cli.CliFrontend.lambda$mainInternal$9(CliFrontend.java:1189) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898) at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.mainInternal(CliFrontend.java:1189) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1157)
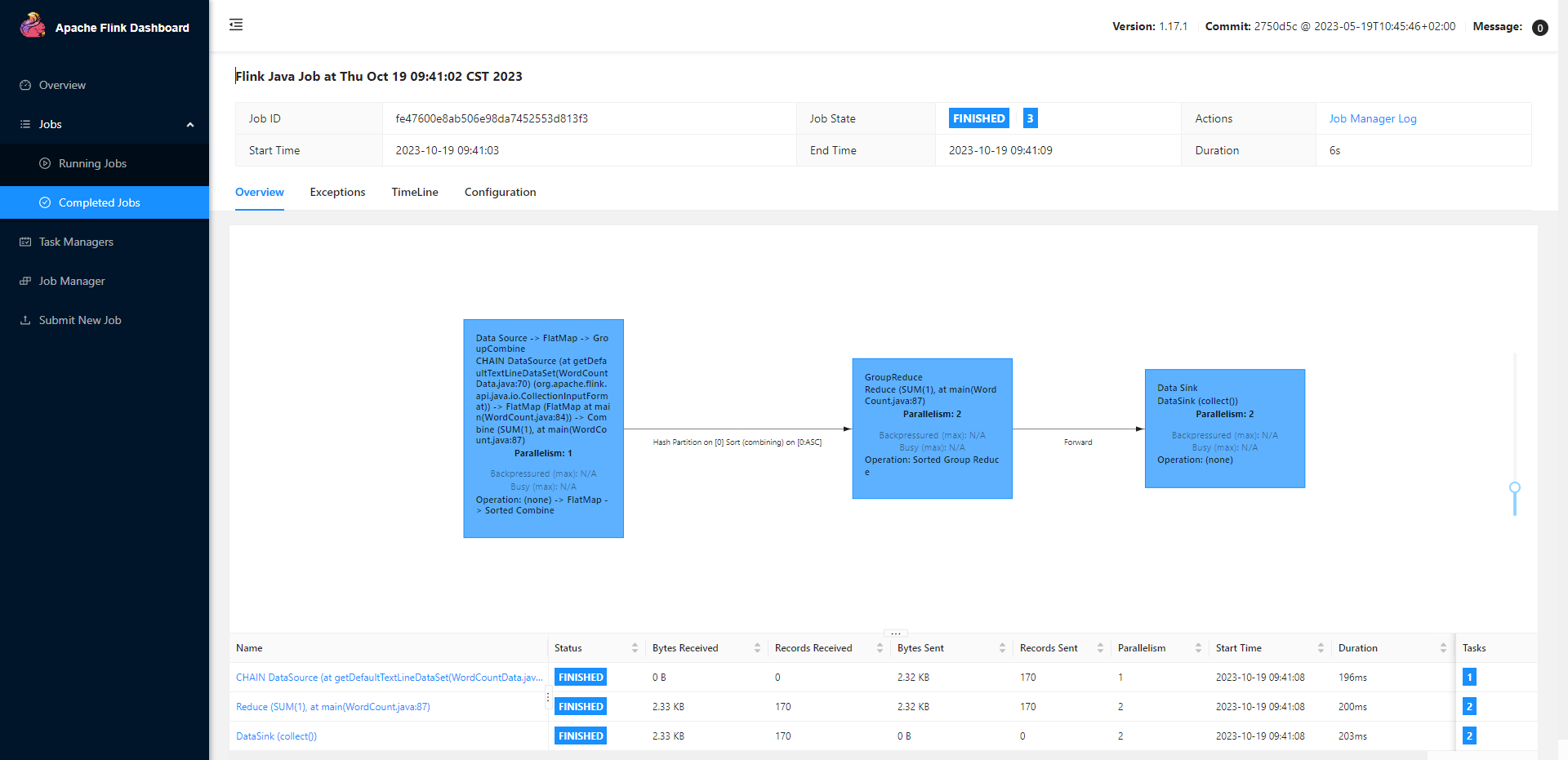
[hadoop@hadoop001 flink]$bin/flink run -d -t yarn-per-job -c org.apache.flink.streaming.examples.windowing.TopSpeedWindowing examples/streaming/TopSpeedWindowing.jar
注意:如果启动过程中报如下异常。
1 2
Exception in thread “Thread-5” java.lang.IllegalStateException: Trying to access closed classloader. Please check if you store classloaders directly or indirectly in static fields. If the stacktrace suggests that the leak occurs in a third party library and cannot be fixed immediately, you can disable this check with the configuration ‘classloader.check-leaked-classloader’. at org.apache.flink.runtime.execution.librarycache.FlinkUserCodeClassLoaders
Job was submitted in detached mode. Results of job execution, such as accumulators, runtime, etc. are not available. Please make sure your program doesn't call an eager execution function [collect, print, printToErr, count]. org.apache.flink.core.execution.DetachedJobExecutionResult.getAccumulatorResult(DetachedJobExecutionResult.java:56) org.apache.flink.api.java.DataSet.collect(DataSet.java:419) org.apache.flink.api.java.DataSet.print(DataSet.java:1748) org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:96)
The program finished with the following exception:
org.apache.flink.client.program.ProgramInvocationException: The main method caused an error: No ExecutorFactory found to execute the application. at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:372) at org.apache.flink.client.program.PackagedProgram.invokeInteractiveModeForExecution(PackagedProgram.java:222) at org.apache.flink.client.ClientUtils.executeProgram(ClientUtils.java:105) at org.apache.flink.client.cli.CliFrontend.executeProgram(CliFrontend.java:851) at org.apache.flink.client.cli.CliFrontend.run(CliFrontend.java:245) at org.apache.flink.client.cli.CliFrontend.parseAndRun(CliFrontend.java:1095) at org.apache.flink.client.cli.CliFrontend.lambda$mainInternal$9(CliFrontend.java:1189) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1898) at org.apache.flink.runtime.security.contexts.HadoopSecurityContext.runSecured(HadoopSecurityContext.java:41) at org.apache.flink.client.cli.CliFrontend.mainInternal(CliFrontend.java:1189) at org.apache.flink.client.cli.CliFrontend.main(CliFrontend.java:1157) Caused by: java.lang.IllegalStateException: No ExecutorFactory found to execute the application. at org.apache.flink.core.execution.DefaultExecutorServiceLoader.getExecutorFactory(DefaultExecutorServiceLoader.java:88) at org.apache.flink.api.java.ExecutionEnvironment.executeAsync(ExecutionEnvironment.java:1043) at org.apache.flink.client.program.ContextEnvironment.executeAsync(ContextEnvironment.java:144) at org.apache.flink.client.program.ContextEnvironment.execute(ContextEnvironment.java:73) at org.apache.flink.api.java.ExecutionEnvironment.execute(ExecutionEnvironment.java:942) at org.apache.flink.api.java.DataSet.collect(DataSet.java:417) at org.apache.flink.api.java.DataSet.print(DataSet.java:1748) at org.apache.flink.examples.java.wordcount.WordCount.main(WordCount.java:96) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.flink.client.program.PackagedProgram.callMainMethod(PackagedProgram.java:355) ... 12 more


 wechat
wechat alipay
alipay