
设计模式之单例模式
0x00.单例模式的定义
单例模式确保某个类只有一个实例,而且自行实例化并向整个系统提供这个实例。
0x01.单例模式的特点
单例类只能有一个实例。
单例类必须自己创建自己的唯一实例。
单例类必须给所有其他对象提供这一实例。
0x02.单例模式的应用
在计算机系统中,线程池、缓存、日志对象、对话框、打印机、显卡的驱动程序对象常被设计成单例。
这些应用都或多或少具有资源管理器的功能。每台计算机可以有若干个打印机,但只能有一个Printer Spooler,以避免两个打印作业同时输出到打印机中。每台计算机可以有若干通信端口,系统应当集中管理这些通信端口,以避免一个通信端口同时被两个请求同时调用。总之,选择单例模式就是为了避免不一致状态。
0x03.单例模式的Java代码
单例模式分为懒汉式(需要才去创建对象)和饿汉式(创建类的实例时就去创建对象)。
0x04.饿汉式
属性实例化对象
12345678910111213//饿汉模式:线程安全,耗费资源。public class HugerSingletonTest { //该对象的引用不可修改 private stati ...
解决Wordpress耗尽可允许分配内存的问题
起因
最近想要在博客中增加 Google AdSense,安装了 WordPress 插件,打开博客管理后台时,一直加载不出来。以为开了代理的问题,关掉代理,发现依然打不开。猜想可能是安装的插件有问题,导致加载失败。登录到服务器,查看 nginx 的日志。
错误日志
在 nginx 的 error.log 发现了如下信息FastCGI sent in stderr: "PHP message: PHP Fatal error: Allowed memory size of 33554432 bytes exhausted (tried to allocate 32768 bytes) ,排除是插件导致的问题。
这个问题发生的原因是,PHP 程序已耗尽了可允许分配的最大内存 33554432 bytes,也就是 32 MB,尝试分配 32768 字节时发生了致命的错误。那就是说,我们在 php 服务的配置 memory_limit 是 32MB,这个值太小,需要修改该值。
1234019/11/23 14:24:50 [error] 16258#16258: *490568 ...
Mac之Catalina OS中编译OpenJDK8
为什么编译JDK
如果想深入学习JDK内部的实现机制,最便捷的路径是自己手动编译一套JDK,通过阅读和跟踪debug JDK源码去深入了解Java技术体系的原理,结合各类书籍、文章和博客,对比理解,更容易让你了解JDK是怎么运作的,底层都做了什么。
环境准备
Mac OS X Catalina 10.15.1
安装依赖软件
Xocde 11
xcode-select
1$ xcode-select install
Homebrew
Mercurial
1$ brew install mercurial
XQuartz
和UI界面有关, build需要引入。
JDK 8
1234$ java -versionjava version "1.8.0_162"Java(TM) SE Runtime Environment (build 1.8.0_162-b12)Java HotSpot(TM) 64-Bit Server VM (build 25.162-b12, mixed mode)
freetype
FreeType是一个用C语言实现的一 ...
多SSH KEY切换部署同步代码
需求场景
大部分开发者个人的代码基本都同步在代码托管平台管理,业内著名的有github、gitlab等,国内也有开源中国的码云(gitee)平台、coding.net平台。有时候,想玩一些有趣的东西,比如用流行的 CMS 搭建一套自己的博客系统(比如 Wordpress),而这些 CMS 都支持在线更新功能、打补丁 fix bug,增加一些合适的插件等。这样我们可以直接在管理后台选择更新系统,而无需先下载到本地,再通过FTP等方式上传到服务器重新部署。
我们喜欢用一些免费的云服务,但都有时长限制,说不定哪天就把我们的服务干掉了,毕竟免费的,服务稳定性不能保障。所以,这些云服务器只能运行代码,却不能做代码托管。于是,我们每次在线更新完功能之后,需要把代码备份到代码托管平台。
一般情况下,我们会单独生成一个 ssh key 公钥用于备份数据,而不是和其他公钥混合使用,避免因为因为某些操作不安全,造成代码丢失。当然你也可以选择一个其他账户操作也是可以的,但如果选择其他账户了,也就没有这篇文章的存在了。还是回到多个 ssh key 的问题上,默认情况下,RSA 算法的 ssh 私钥文件名为id ...
CentOS安装docker与代理设置
CentOS安装docker
注意:不要采用yum直接安装CentOS repository自带的docker。
1. 安装
先卸载已有的docker环境:
12345678910yum remove docker \ docker-client \ docker-client-latest \ docker-common \ docker-latest \ docker-latest-logrotate \ docker-logrotate \ docker-selinux \ docker-engine-selinux \ docker-engine
安装所需的软件包。yum-utils提供了yum-config-manager功能,而device-mapper-persistent-data和lvm2是devicemapper存储驱动程序所需。
123yum in ...
Mac中编译Nginx源码1.17
背景
使用Mac的开发者大多数的时候通过 brew 命令安装各类软件,比如 PHP、Python、Nodejs,Nginx 也不例外。
默认情况下Nginx安装在/usr/local/Cellar/nginx,通过brew link nginx加软连接到/usr/local/bin/nginx,虽然这样完全满足开发且符合 Mac 软件的管理,但是却不方便移植(比如想给不懂开发的用户一键部署部署的应用包,做私有化部署的同学应该对此不陌生)。
从源码编译NGINX程序比安装预编译的安装包要灵活很多,可以添加特定的模块(来自NGINX官方或者第三方的,比如给 Fastdfs 提供 HTTP 访问文件能力的 fastdfs-nginx 模块),当然自己编译源码拉取的可以是已修复 bug 和新增特性的最新分支。
编译
依赖
PCRE——支持正则表达式。 是 Nginx 的核心和重写模块的所需依赖库。
12wget https://ftp.pcre.org/pub/pcre/pcre-8.43.tar.bz2tar zxf pcre-8.43.tar.bz2
zlib——支持标头压缩。是 ...
理解Flink的窗口和水印
Windows窗口定义
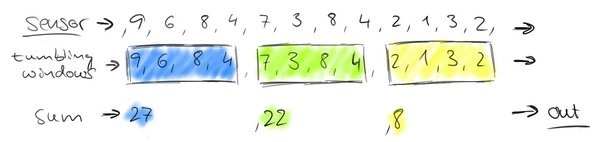
按固定时间区间计算该区间的值,例如15s计算汇总一次:
无穷的流,数据不间断的,例如有累计数据的需求,按上图的逻辑是处理不到的。换一种思路,每隔 15 秒,我们都将与上一次的结果进行 sum 操作(滑动聚合):
流是无界的,我们不能限制流,所以上述方案也解决不了需求,但可以在有一个有界的范围内处理无界的流数据。
那么按一分钟一个时间窗口计算,相当于一个定义了一个 Window(窗口),window 的界限是1分钟,且每分钟内的数据互不干扰,因此也可以称为滚动(不重合)窗口
第一分钟的数量为8,第二分钟是22,第三分钟是27。。。这样,1个小时内会有60个window。
再考虑一种情况,每30秒统计一次过去1分钟的数量之和:
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window 又可以分为基于时间(Time-based)的 window 以及基于数量(Count-based)的 window。
Flink窗口类型
对于窗口的操作主要分为两种,分别对于 Keyedstream 和 Datastr ...
初探流式计算框架Flink
介绍
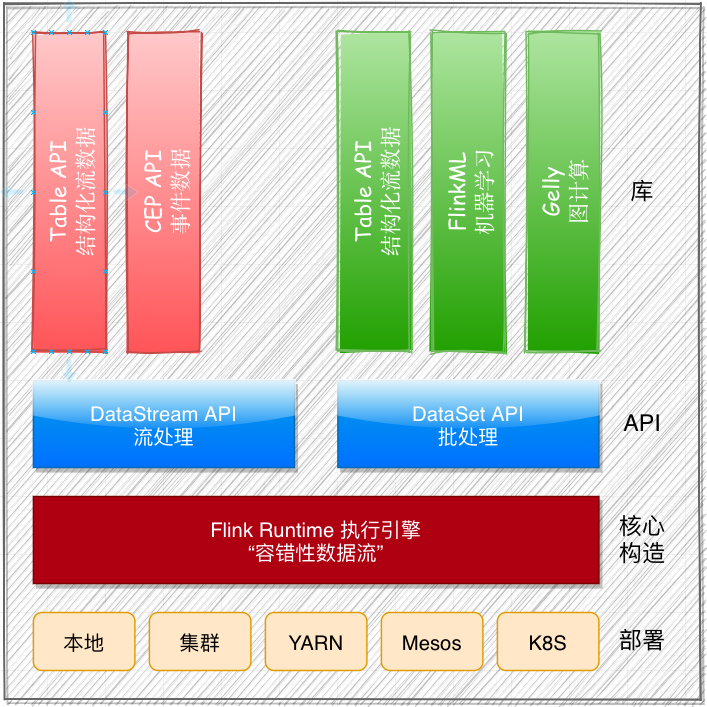
Apache Flink 是为分布式、高性能、随时可用以及准确的流处理应用程序打造的开源流处理框架。Flink不仅能同时提供支持高吞吐和严格一次(exactly-once)语义的实时计算,还能提供批量数据处理。
Apache Flink 是一个用于对无边界和有边界数据流进行有状态计算的框架和分布式处理引擎。Flink被设计为可在所有常见的集群环境中运行、并能以内存速度和任意规模进行计算。
处理无界和有界数据
任何类型的数据都是作为事件流产生的,比如信用卡交易、传感器测量、机服务器日志、网站或者移动应用程序的用户交互,所有这些数据均作为流生成。
然后,这些数据,可以作为有界流或者无界流来来处理。
无界流有一个起点,但没有确定的终点。它们不会终止并在生成数据时提供数据,无界流必须连续的处理,即,事件在被提取后必须立即处理,无法等待所有输入数据到达再处理,因为输入是无界的,并且在任何时间都不会完成。处理无界数据通常要求以特定的顺序(例如时间发生的顺序)提取事件,以便能够推测出结果的完整性。处理无界流也成为流处理。
有界流具有确定的开始和结束。可以通过在执行任何计算之前提取所有数据来处 ...
浅谈分布式锁
为什么要有分布式锁
随着架构系统的演进,由纯真的单机架构到容器化编排的分布式架构,可以说是一个大型互联网企业发展的必然走向。在网站初创时,应用数量和用户较少,可以把 Tomcat 和Mysql 部署在同一台机器上。随着用户数量增多,访问量增大,并发升高,Tomcat 和 MySQL 竞争资源,此时,单机已经扛不住了,需要把 Tomcat 和 MySQL 分离在不同的机器上,用于提升单台机器的处理能力。业务从来没有减少,产品越做越大。应用也越来越复杂,原来的大应用,拆分成多个小应用,加入各级缓存,做了反向代理负责均衡,最后坠入分库分表的深渊。
微服务渐渐代替了庞大冗杂的服务,每个小服务,各司其职。这时候是不是就不存在资源竞争的问题了呢?答案毋庸置疑,在架构的演进过程中,无时无刻都存在着资源竞争的问题。
说起资源竞争的问题,是不是想起了在计算机科学中的一个经典问题——哲学家就餐,也就是在并行计算中多线程同步( Synchronization )时产生的问题?哲学家就餐问题用来解释死锁和资源耗尽的问题,我们不做详细的讨论,感兴趣的同学可以搜索资料了解。既然存在资源竞争的问题,解决的方案必然是 ...
Netty在AI质检引擎中的实践
需求和设计方案
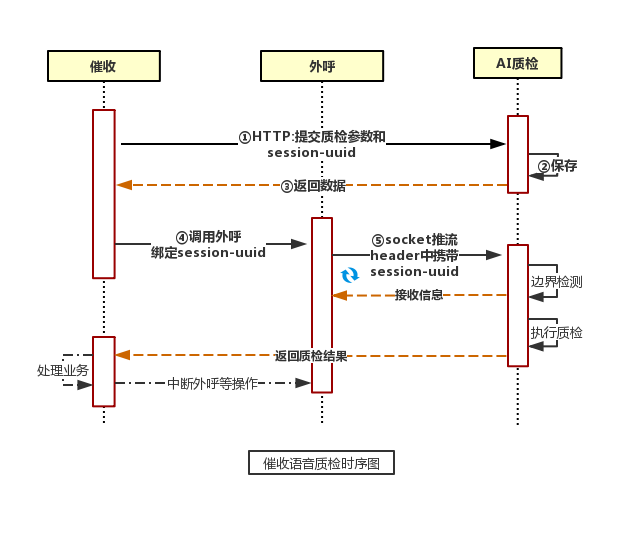
实时质检的复杂度在于外呼系统数据流的边界切割,为了便于和催收平台对接,我们重新设计了接口,把音频流的切割放在AI平台,外呼系统仅需要将音频流数据通过socket推送到AI质检系统即可。
尽管如此,依然无法完全解决产品需求,Socket Header不能携带更多的质检配置信息,亦不能在数据流中既推送文本配置信息(比如授权、规则集等)又推送流媒体,因此,我们又鉴于此设计了Http接口,上传需要本次催收通话中语音质检的配置信息。
上图,是初步设计的数据流时序图。催收平台通过HTTP接口提交质检所需的数据(appKey,appSecret,strategySign)以及一个全局唯一的会话字段session-uuid,AI质检系统将其保存在本地缓存中,为后续的质检提供服务。之后,催收系统在调用外呼系统时,将session-uuid绑到socket协议的header中,AI系统解析外呼系统推送的socket中header信息,并在本地缓存中查找与之对应的质检配置信息,然后处理音频流,切割成不同的片段质检,并将质检结果通过回调接口传给催收平台(AI平台有质检记录,可通过sessio ...